类脑认知智能引擎“智脉(BrainCog)”荣获Cell出版社2023中国年度论文
字号:【大】 【中】 【小】
中国科学院自动化研究所类脑认知智能实验室在团队负责人曾毅研究员的带领下,历时十余年,研发了基于全脉冲神经网络的类脑认知智能引擎“智脉(BrainCog)”,旨在为通用人工智能的探索提供理论支撑和技术实现路径。
智脉凭借其科学性与创新性,于2023年被Cell出版社旗下Patterns期刊刊发为封面文章,并被评为Cell出版社2023中国年度论文。这一荣誉充分肯定了智脉在类脑智能领域的前沿地位,也彰显了其作为开源平台在推动学术研究、技术创新与产业应用协同发展中的重要作用。




作为一个面向全球的开源类脑人工智能平台,“智脉”不仅支持基础研究与算法开发,还为行业应用提供了高度灵活的工具链。平台组件涵盖了多尺度生物可塑性法则、丰富的脉冲神经网络架构和多模态数据接口,形成从脑模拟到类脑智能应用的全栈解决方案。智脉以推动全球研究者和开发者的协作为使命,目前已广泛部署至GitHub和OpenI启智社区等平台,累计下载量超过万次,并持续在国际学术和产业界引发关注。
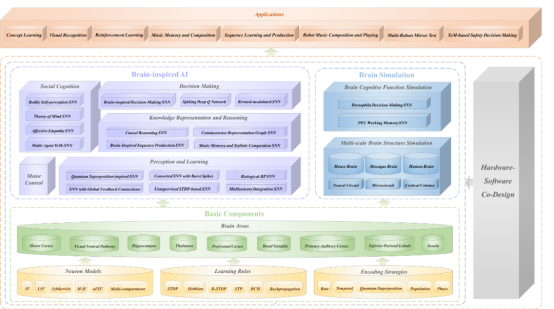
图1:类脑认知智能引擎“智脉”BrainCog的计算组件与应用
在过去的一年里,智脉团队围绕“高智能”“低能耗”和“软硬件协同适配”三大核心方向开展深入研究,取得了多项突破性成果。通过模拟脑神经元的活动规律、突触的动态可塑性,以及神经网络结构的发育与演化,智脉不仅解决了复杂任务中的计算挑战,还以极低的能耗展现了接近生物脑的认知表现。这一特性为未来类脑大模型的开发奠定了基础,同时推动了神经形态计算、认知科学和人工智能技术的交叉融合。这些工作成果分别发表在多个顶级期刊和会议上,包括PNAS、Cell旗下期刊iScience、Nature旗下期刊Scientific Data、IEEE TPAMI、TEVC、TCAD、TCAS-I和TVLSI等顶级期刊以及IJCAI、CVPR、NeurIPS等顶级会议,展示了团队在多学科领域的创新能力。
面向通用高智能的智脉(BrainCog)进展
智脉(BrainCog)在推动通用高智能发展方面持续突破,聚焦发育和演化两大核心主题,构建类脑脉冲神经网络(SNN)的新架构与能力,显著提升了其在感知、学习、决策等高级认知任务中的表现。
脑启发的神经回路演化:赋能高智能决策与学习
人脑中不同类型的神经环路及其自适应能力促进了人类感知、学习、决策及其他高等认知功能的实现。当今多数脉冲神经网络结构的设计仍然借鉴传统深度学习的架构,并没有充分融入和发挥目前我们对人脑结构自适应机制的作用,因此也就没有在结构和机制方面相对充分地反映出类脑脉冲神经网络的特性。BrainCog团队引入类脑兴奋性、抑制性神经元和前馈反馈连接这些基本计算组件的基础上,将局部无监督学习规则与结构演化机理相融合,生成具有生物合理性的神经环路结构。通过结合全局误差信号,演化出的类脑脉冲神经网络在感知、强化学习与决策方面显著增强了其能力。相关研究成果Brain-inspired neural circuit evolution for spiking neural networks发表在 Proceedings of the National Academy of Sciences, (PNAS)。
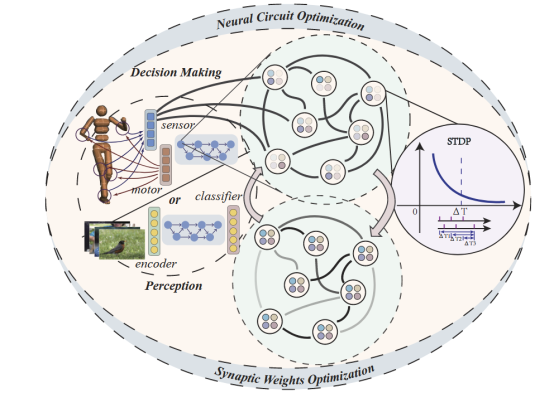
图2:利用脑启发神经演化构建的类脑脉冲神经网络
文章链接为:https://www.pnas.org/doi/abs/10.1073/pnas.2218173120
跨尺度神经架构搜索:突破多层次协同演化
人脑多尺度的结构可塑性如兴奋/抑制性神经元协同的多样神经微环路、跨脑区的长程连接等作为基本组件,自组织地形成错综复杂又高效的神经系统。受此启发,BrainCog团队协同演化多尺度的类脑脉冲神经网络结构,从微观神经元到介观神经motifs以及宏观全局连接的基因搜索空间,以类脑的高效间接适应性函数自然选择出更具适应性、通用性、泛化性的类脑SNN。在多个静态和神经形态数据集上,类脑多尺度演化SNN自然而然地带来更高性能、更低能耗、更强鲁棒、跨任务的可迁移能力以及适应能力。相关研究成果Brain-inspired Multi-scale Evolutionary Neural Architecture Search for Spiking Neural Networks已经被IEEE Transactions on Evolutionary Computation (TEVC) 接受。
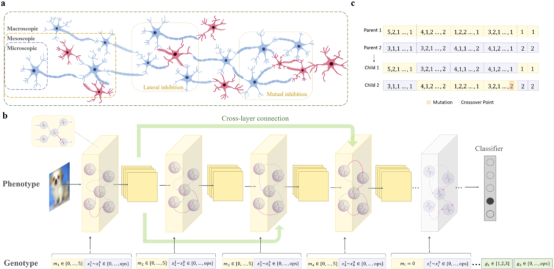
图3:多尺度脉冲神经网络演化
文章链接为:https://arxiv.org/abs/2304.10749
小世界网络的自组织涌现:高效拓扑结构的创新
BrainCog团队以生物脑高效的小世界拓扑属性为基础,以静态小世界系数和动态临界稳态为适应性函数,通过多目标演化随机连接的蓄水池脉冲神经网络,引导其涌现出类脑的模块化结构、Hub节点等高效的类脑拓扑属性,提升演化效率的同时在多类任务上展现出高性能、低能耗等特点。相关研究成果Emergence of Brain-inspired Small-world Spiking Neural Network through Neuroevolution发表在Cell旗下期刊iScience上。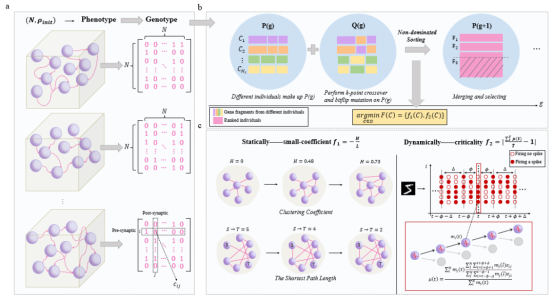
图4:多目标演化蓄水池网络
文章链接为:https://www.cell.com/iscience/fulltext/S2589-0042(24)00066-X
发育可塑性驱动的自适应剪枝:提升网络效率
融合生物脑多尺度发育可塑性机制,例如:树突棘动态可塑性、局部突触可塑性和活动依赖的神经元脉冲迹等,基于“用进废退”的原则设计自适应剪枝策略去除网络中冗余的突触和神经元,探索脑发育可塑性如何赋予深度神经网络以动态结构调整能力,使其像生物脑一样逐步“发育”为更高效的结构。BrainCog团队提出的通用发育可塑性自适应剪枝方法在深度神经网络和脉冲神经网络中均对性能和效率有显著提升。相关研究成果Developmental Plasticity-inspired Adaptive Pruning for Deep Spiking and Artificial Neural Networks发表于IEEE Transactions on Pattern Analysis and Machine Intelligence(IEEE TPAMI)。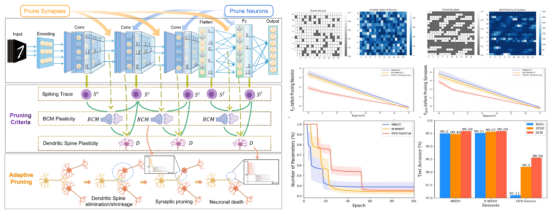
图5:发育可塑性自适应剪枝方法及其剪枝过程
文章链接为:https://ieeexplore.ieee.org/document/10691937
动态结构发育的连续学习:高效知识复用
受大脑神经通路动态扩展和收缩的结构发育机制的启发,BrainCog团队提出了脉冲神经网络的动态结构发育连续学习算法。该模型通过动态地生长,修剪和共享神经元,能够充分复用过去获得的知识帮助新任务的学习,在提升连续学习性能的同时增加记忆容量,降低计算开销。相关研究成果Enhancing Efficient Continual Learning with Dynamic Structure Development of Spiking Neural Networks发表于International Joint Conference on Artificial Intelligence 2023 (IJCAI2023)会议。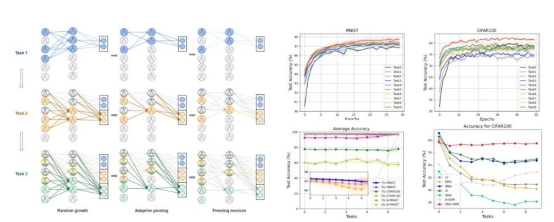
图6:基于动态结构发育的脉冲神经网络模型及其性能
文章链接为:https://www.ijcai.org/proceedings/2023/334
面向低功耗的智脉(BrainCog)进展
智脉(BrainCog)通过开发新型数据集与优化算法,进一步夯实类脑人工智能的理论基础与实践能力,迈向高效节能与认知智能融合的目标。
N-Omniglot:小样本学习的神经形态数据集
深度学习的成功离不开ImageNet和COCO等数据集,但类脑智能,特别是脉冲神经网络(SNN)缺乏适用的数据集。DVS传感器模拟了人类视觉神经系统,提供了丰富的时间信息,但现有数据集如N-MNIST、DVS-Gesture等时间相关性较低,限制了SNN的潜力。为解决这一问题,BrainCog团队开发了首个面向小样本学习的神经形态数据集N-Omniglot。相关研究成果N-Omniglot, a large-scale neuromorphic dataset for spatio-temporal sparse few-shot learning发表在Nature出版社旗下期刊Scientific Data上。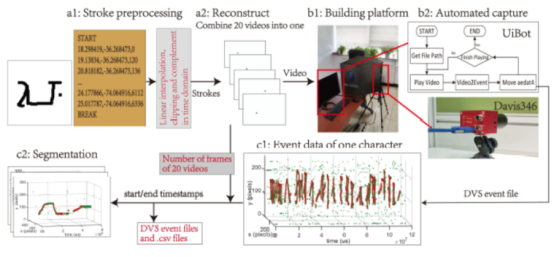
图7:N-Omniglot数据生成的完整过程
文章链接为:https://www.nature.com/articles/s41597-022-01851-z
Bullying10K:隐私保护下的行为识别数据集
公共区域的监控摄像头已经对减少暴力事件产生了积极影响,但同时也引发了关于隐私侵犯的担忧。为了应对这一问题,BrainCog团队利用了DVS摄像头的特性,创建了Bullying10K神经形态数据集。数据集包含了1万个事件片段,共计120亿个事件和255GB的数据。与传统摄像头不同,DVS摄像头通过监测像素的亮度变化生成事件流,使得内容识别更为困难。Bullying10K强调对复杂、快速和可能遭遮挡的动作的捕捉,为神经形态研究带来新的视角。利用这种方法,我们可以在检测暴力行为的同时,确保参与者的隐私得到保护。我们期望此数据集能够为未来相关领域的研究提供宝贵的数据并提供新的数据保护方式的机会。相关研究成果Bullying10K: a large-scale neuromorphic dataset towards privacy-preserving bullying recognition发表在Advances in Neural Information Processing Systems, 2024 (NeurIPS 2024)。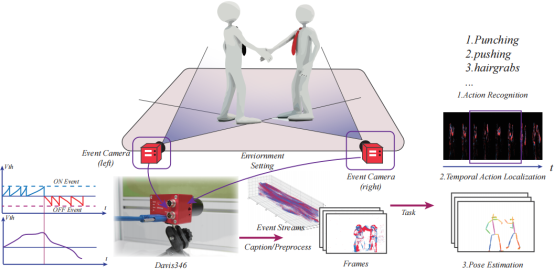
图8:Bullying10K的拍摄过程以及基准任务
文章链接为:https://proceedings.neurips.cc/paper_files/paper/2023/hash/05ffe69463062b7f9fb506c8351ffdd7-Abstract-Datasets_and_Benchmarks.html
网络量化与能耗优化的新视角
BrainCog团队从网络量化的角度重新审视脉冲神经网络的能效优势,探讨其与量化人工神经网络的公平对比问题。提出了一种统一视角,将SNN中的时间步数与ANN中激活值的量化位宽建立类比关系,并在此基础上提出了一种更务实、合理的SNN能耗估算方法。与传统的突触操作(SynOps)衡量标准不同,BrainCog团队引入了“位预算”(Bit Budget)的新概念,以探讨在严格硬件约束下,如何在权重、激活值和时间步之间合理分配计算和存储资源。在位预算指导下,研究表明,与注重时间步数相比,将关注点转向脉冲模式和权重量化对模型性能提升具有更深远的影响。通过位预算对SNN的整体设计进行优化,本文在静态图像和神经形态数据集上显著提升了模型性能,并为SNNs与量化ANNs之间的理论差距架起了桥梁,为实现更高能效的神经计算提供了切实可行的路径。相关研究成果Are Conventional SNNs Really Efficient? A Perspective from Network Quantization发表在IEEE/CVF Conference on Computer Vision and Pattern Recognition 2024 (CVPR24)上。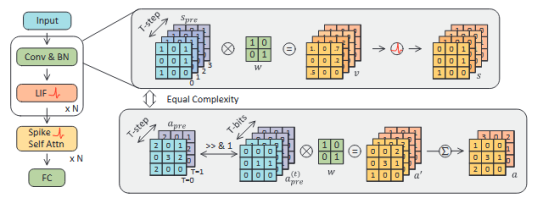
图9:在相同的特征比特数下,snn和量化ann具有相同的表示复杂度。
文章链接为:https://ieeexplore.ieee.org/document/10656053/
TIM: 提升时序建模能力的高效时序交互模块
尽管Spiking Transformer在图像任务上取得了不俗的性能,但仅依靠LIF神经元的膜电势无法很好地建模输入的时序信息。因此BrainCog设计了Temporal Interaction Module(TIM)用于模型对时序表征的提取和分析能力。TIM参数量极小,保留了SNN应有的高效性和低能耗,同时大幅提升了Spiking Transformer建模时序信息的能力。相关研究成果TIM:An Effcient Temporal Interaction Module for Spiking Transformer发表在International Joint Conference on Artificial Intelligence 2024 (IJCAI2024)会议上。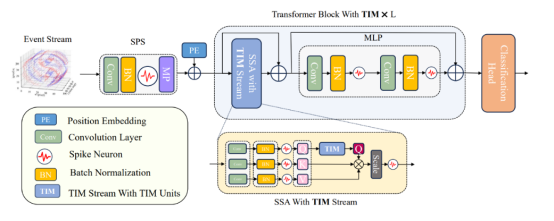
图10:TIM框架示意图
论文链接:https://www.ijcai.org/proceedings/2024/0347.pdf
智脉·萤火系列:软硬件协同的类脑智能硬件创新
“智脉·萤火(FireFly)”是具有运算和访存优化的高吞吐率类脑脉冲神经网络加速器,与“智脉(BrainCog)”深度融合并进行软硬件协同创新,支持基于边缘计算的脉冲神经网络低能耗、高性能、高智能应用。“智脉·萤火”(BrainCog FireFly)系列工作的不断推进,为探索软硬件协同的类脑人工智能的无限可能性注入了更坚实的信心。我们始终坚信,在相对小规模的软硬件协同平台上实现低功耗、高性能与高智能的融合才是未来真正意义的人工智能的走向与趋势。
智脉萤火 (Firefly)
智脉萤火 (Firefly)是一个具有突触运算优化和访存层级优化的高吞吐率SNN加速器,该工作充分利用了Xilinx Ultrascale器件中的专用运算模块DSP48E2实现SNN的高效运算;该工作设计了一个内存系统实现高效的突触权重和膜电压内存访问。FireFly作为一个轻量级加速器,与现有的使用大型FPGA设备的SNN加速器相比实现了更高的运算效率,达到了5.53TOP/s的运算吞吐率。相关研究成果FireFly: A High-Throughput Hardware Accelerator for Spiking Neural Networks With Efficient DSP and Memory Optimization发表在IEEE Transactions on Very Large Scale Integration (VLSI) Systems上。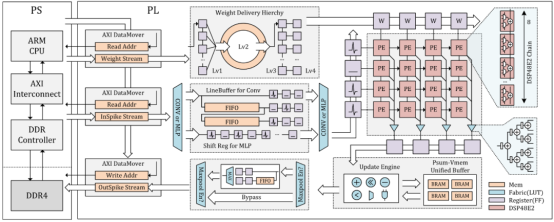
图11:FireFly V1示意图
文章链接为:https://ieeexplore.ieee.org/abstract/document/10143752
智脉萤火-凌波 (Firefly-v2)
智脉萤火-凌波 (Firefly-v2)是一个与算法俱进的高性能类脑SNN加速器。该工作设计了一种比特分解的机制从硬件的角度去对SNN中多比特脉冲不友好算子进行适配。该工作对传统的数据流模式进行了优化,通过解决运算时程依赖消除了昂贵的片内膜电位存储需求。该研究引入了双倍时钟频率技术,实现了运算单元时钟频率的翻倍,相比起现有的基于FPGA的SNN加速器,如DeepFire2,有着40%的运算单元利用效率的提升,并相比起一代有着显著的性能提升。相关研究成果FireFly v2: Advancing Hardware Support for High-Performance Spiking Neural Network with a Spatiotemporal FPGA Accelerator发表在IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems(TCAD)上。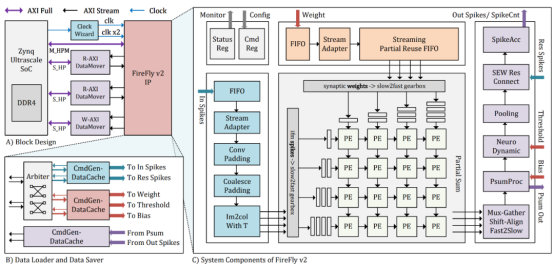
图12:FireFly V2示意图
文章链接为:https://ieeexplore.ieee.org/abstract/document/10478105
智脉萤火-疏影(Firefly-S)
智脉萤火-疏影(Firefly-S)是一个利用双边稀疏性加速的软硬件协同工作。该工作在算法层面针对SNN的神经元特性创新了硬件友好的学习步长量化策略,并与基于梯度重布线的剪枝机制相结合,得到了高度压缩且在权重和神经元脉冲层面都具有稀疏性的模型。在硬件层面该研究优化了基于空间架构的数据流以及引入了双边稀疏加速单元,能够有效减少层间流水停滞周期以及去除计算过程中冗余的包含零值的计算,进而提高推理速率。相比起前代基于密集计算的FireFly系列有着6x-20x的能效比,同时与现有的单边稀疏加速器对比,如SyncNN,在更小的硬件平台上实现了近2倍的能效比。相关研究成果FireFly-S: Exploiting Dual-Side Sparsity for Spiking Neural Networks Acceleration With Reconfigurable Spatial Architecture发表在IEEE Transactions on Circuits and Systems I: Regular Papers(TCAS-I)上。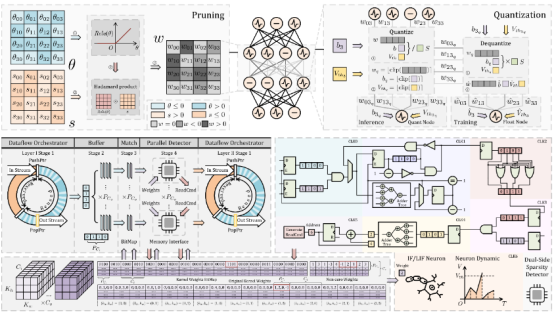
图13:FireFly S示意图
文章链接为:https://ieeexplore.ieee.org/document/10754657
版权所有 © 脑图谱与类脑智能实验室
备案序号:京ICP备14019135号-3 京公网安备110108003079号
地址:北京市海淀区中关村东路95号 邮编:100190 mail:brain-ai@ia.ac.cn