Laboratory Paper Accepted at NeurIPS 2023
Font:【B】 【M】 【S】
NeurIPS, short for the Conference on Neural Information Processing Systems, is a top-tier international conference in the fields of machine learning and computational neuroscience. This article introduces one paper from the Laboratory of Brain Atlas and Brain-Inspired Intelligence, Institute of Automation, Chinese Academy of Sciences, accepted at NeurIPS 2023.
Spike-driven Transformer
Authors: Yao Man, Hu Jiakui, Zhou Zhaokun, Yuan Li, Tian Yonghong, Xu Bo, Li Guoqi
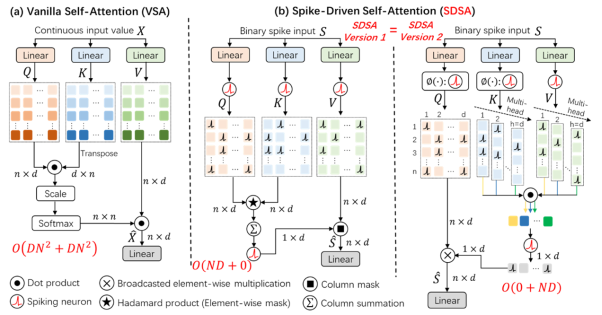
This paper proposes the first Spike-driven Transformer, in which the entire network uses only sparse addition. The proposed Spike-driven Transformer has four distinctive properties: (1) Event-driven: computation is not triggered when the Transformer input is zero; (2) Binary spike communication: all matrix multiplications involving spike matrices can be converted into sparse additions; (3) The designed self-attention mechanism achieves linear complexity along both token and channel dimensions; (4) Computations between spike-form Query, Key, and Value matrices reduce to masking and addition. In summary, the network only performs sparse addition operations. To achieve this, the paper introduces a novel Spike-Driven Self-Attention (SDSA) operator that uses only masking and addition without any multiplication, resulting in 87.2 times lower energy consumption compared to the original self-attention operator. Additionally, to ensure all signals transmitted between neurons in the network are binary spikes, the paper reorganizes all residual connections. Experimental results show that the Spike-driven Transformer achieves 77.1% top-1 accuracy on ImageNet-1K, representing the best result in the SNN domain.
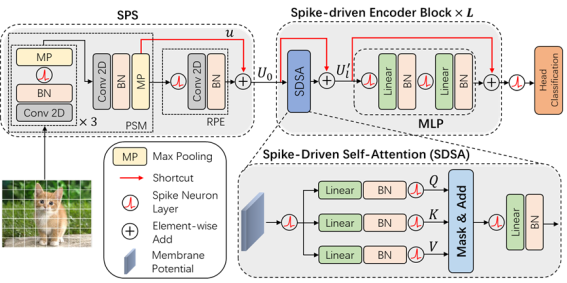
Figure 1. Spike-driven Transformer architecture diagram
Figure 2. Spike-driven Self-Attention operator
Paper link:
https://arxiv.org/abs/2307.01694
Code link:
https://github.com/BICLab/Spike-Driven-Transformer
Copyright Institute of Automation Chinese Academy of Sciences All Rights Reserved
Address: 95 Zhongguancun East Road, 100190, BEIJING, CHINA
Email:brain-ai@ia.ac.cn