Laboratory Has 3 Papers Accepted at the 38th AAAI Conference on Artificial Intelligence
Font:【B】 【M】 【S】
Recently, the AAAI Conference on Artificial Intelligence (AAAI), an A-class international conference recommended by the China Computer Federation (CCF), announced its paper acceptance results. Organized by the Association for the Advancement of Artificial Intelligence, AAAI is one of the top international academic conferences in the field of AI. The 38th AAAI Conference will be held in February 2024 in Vancouver, Canada. This article introduces three papers from the Laboratory of Brain Atlas and Brain-Inspired Intelligence, Institute of Automation, Chinese Academy of Sciences, accepted at AAAI 2024 (in no particular order).
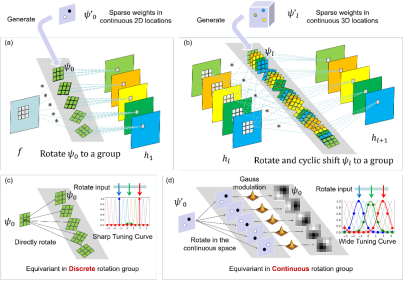
1. Continuous Rotation Group Equivariant Network Inspired by Neural Population Coding
Authors: Chen Zhiqiang, Chen Yang, Zou Xiaolong, Yu Shan
Research Introduction:
Population coding is a common mechanism in biological neurons. For example, ‘place cells’ in the hippocampus and neurons in the primary visual cortex encoding direction, color, and orientation all rely on population coding. Bell-shaped tuning curves are critical for encoding continuous information through discrete optimal stimuli. Inspired by this, we embed bell-shaped tuning curves into discrete group-equivariant convolution via Gaussian modulation, thereby achieving continuous group equivariance using discrete group convolution. Thanks to Gaussian modulation, the convolutional kernels have smooth gradients along geometric dimensions (e.g., position, orientation), enabling the use of sparse, learnable geometric-parameterized weights to generate group-equivariant kernels with both competitive performance and high parameter efficiency. Experimental results show: (1) on MNIST-rot, our method achieves highly competitive performance with fewer parameters (less than 25% of previous methods); (2) especially in few-shot learning, it achieves significant performance gains (24% improvement); (3) it also shows strong rotational generalization across more datasets (e.g., MNIST, CIFAR, ImageNet) and different architectures (plain and ResNet).
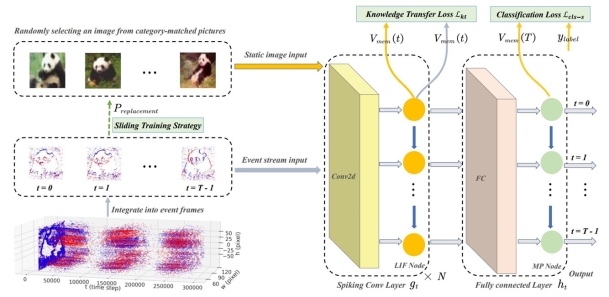
2. An Efficient Knowledge Transfer Strategy for Spiking Neural Networks from Static to Event Domain
Authors: He Xiang, Zhao Dongcheng, Li Yang, Shen Guobin, Kong Qingqun, Zeng Yi
Research Introduction:
Spiking Neural Networks (SNNs) are renowned for their event-driven nature and temporal features, making them suitable for processing event data. However, event datasets are often small in scale, limiting further development. By contrast, static RGB datasets are larger and easier to obtain. Although static images provide valuable spatial information for event data, there is an inherent domain gap between them. To reduce this domain gap and improve SNN performance on event data, we address two main aspects: feature distribution and training strategy. For feature distribution, we design a knowledge transfer loss function comprising domain alignment loss and spatio-temporal regularization. Domain alignment loss reduces marginal distribution distance between static images and event data to learn domain-invariant spatial features. Spatio-temporal regularization provides a dynamically adjusted coefficient to better capture temporal features in the data. For training strategy, we propose a sliding training strategy that probabilistically replaces static image inputs with event data during training, smoothly reducing the effect of knowledge transfer loss and stabilizing training. Experimental results on three datasets fully demonstrate the effectiveness of the proposed method.
Code available at:
https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/transfer_for_dvs
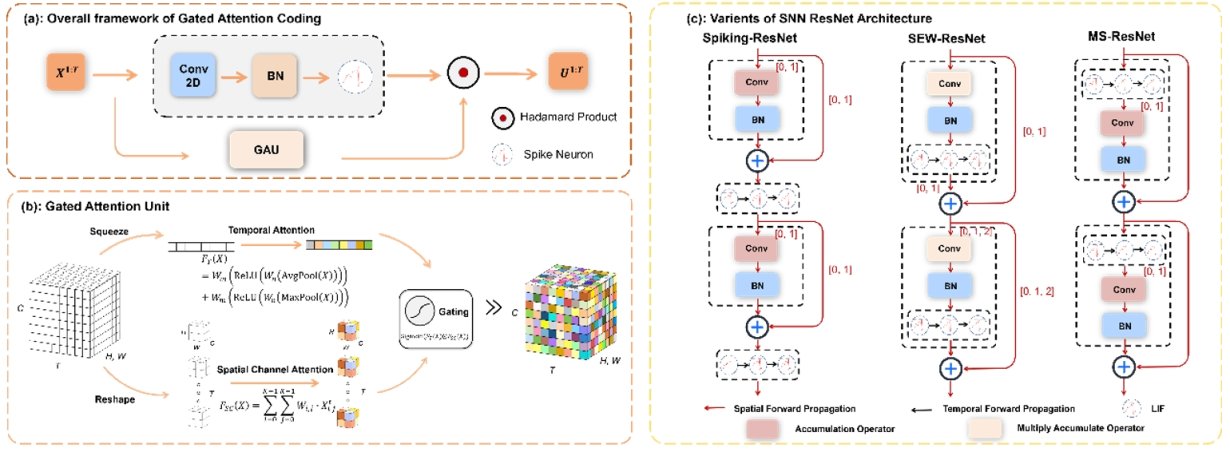
3. Gated Attention Coding for Training High-performance and Efficient Spiking Neural Networks
Authors: Qiu Xuerui, Zhu Ruijie, Chou Yuhong, Wang Zhaorui, Deng Liangjian, Li Guoqi
Research Introduction:
Encoding is crucial in SNNs as it transforms external input stimuli into spatiotemporal feature sequences. Most existing deep SNNs rely on simple direct encoding schemes, resulting in weak spike representations lacking the inherent temporal dynamics of human vision. To address this, we propose Gated Attention Coding (GAC), a plug-and-play module that efficiently encodes inputs into strong representations using multidimensional gated attention units, feeding them into SNN architectures. GAC acts as a preprocessing layer without breaking the spike-based nature of SNNs, making it easy to implement on neuromorphic hardware with minimal modifications. Through observer model theoretical analysis, we show that GAC’s attention mechanism improves temporal dynamics and encoding efficiency. Experiments on CIFAR10/100 and ImageNet show that GAC achieves state-of-the-art accuracy with excellent efficiency. Notably, with only six time steps, GAC improves top-1 accuracy by 3.10% on CIFAR100 and 1.07% on ImageNet while reducing energy consumption to 66.9% of previous work. We are among the first to explore attention-based dynamic encoding for deep SNNs, demonstrating excellent results and efficiency on large-scale datasets.
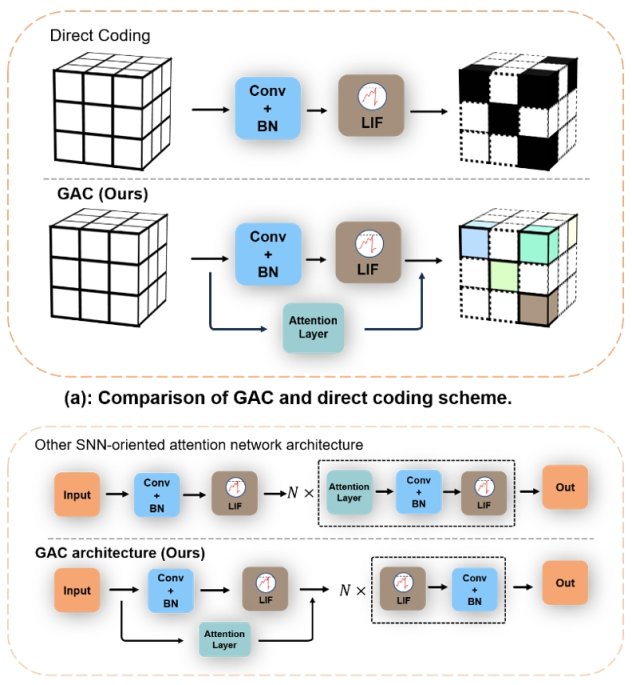
Figure 1. Comparison of Gated Attention Coding (GAC) with other methods
Figure 2. Detailed implementation of Gated Attention Coding (GAC)
Code link:
https://github.com/bollossom/GAC
Copyright Institute of Automation Chinese Academy of Sciences All Rights Reserved
Address: 95 Zhongguancun East Road, 100190, BEIJING, CHINA
Email:brain-ai@ia.ac.cn