Four Papers from the Laboratory Accepted at the 39th AAAI Conference on Artificial Intelligence
Font:【B】 【M】 【S】
The AAAI Conference on Artificial Intelligence, organized by the Association for the Advancement of Artificial Intelligence, is one of the world’s top international academic conferences in AI. The 39th AAAI Conference will be held in February 2025 in Philadelphia, Pennsylvania, USA.
01. Efficient Reinforcement Learning through Adaptively Pretrained Visual Encoder
Authors: Yuhan Zhang (co-first), Guoqing Ma (co-first), Guangfu Hao, Liangxuan Guo, Yang Chen, Shan Yu
Although reinforcement learning (RL) agents can successfully learn complex tasks, generalizing these skills to new environments remains challenging. One underlying reason is that the visual encoders used are task-specific, limiting feature extraction across diverse environments. To address this issue, we propose APE: a framework for efficient reinforcement learning through adaptively pretrained visual encoders. Experimental results show that mainstream RL algorithms equipped with APE achieve consistent performance improvements across multiple environments and significantly enhance learning efficiency. Even when relying only on visual input, the performance approaches that of state-based policies, demonstrating the potential of adaptive encoder pretraining to improve generalization and efficiency in visual RL.
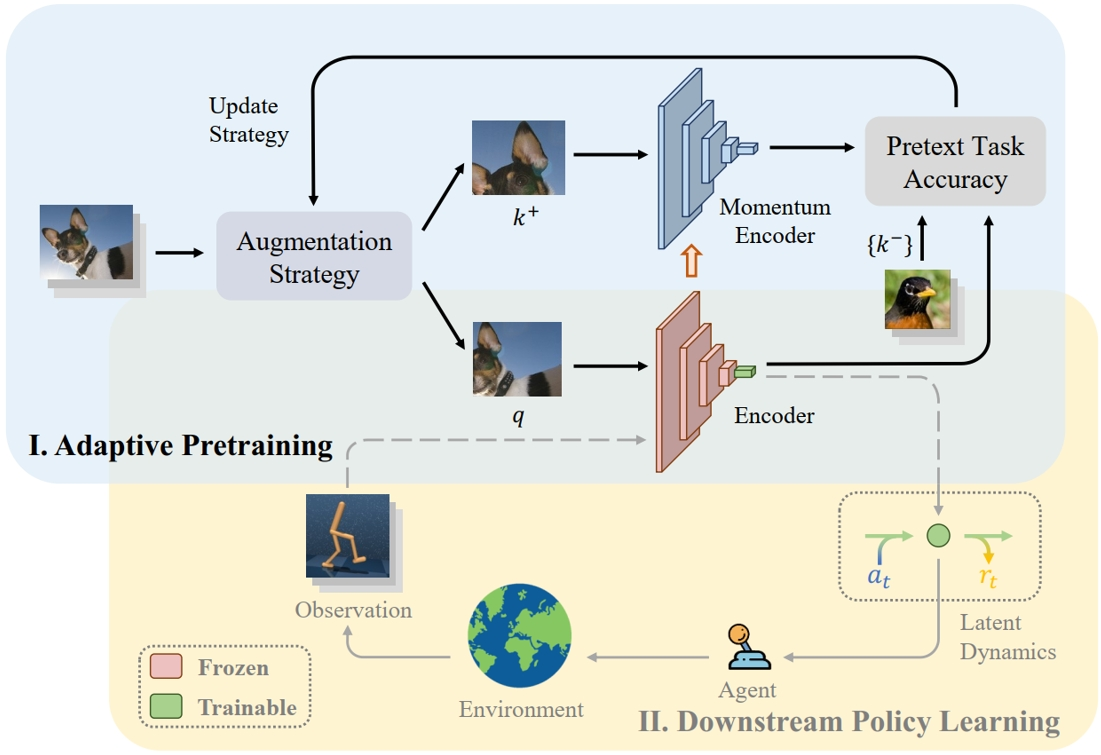
APE framework for model-based reinforcement learning. The training process consists of two parts: the adaptive pretraining phase (blue region) and the downstream policy learning phase (yellow region). In the first phase, an adaptive data augmentation strategy enhances images from various real-world scenes, dynamically updating the sampling probabilities of each augmentation set in the next pretraining cycle. In the second phase, the pretrained visual encoder serves as the perception module within a general RL algorithm framework.
02. Multi-Modal Latent Variables for Cross-Individual Primary Visual Cortex Modeling and Analysis
Authors: Yu Zhu, Bo Lei, Chunfeng Song, Wanli Ouyang, Shan Yu, Tiejun Huang
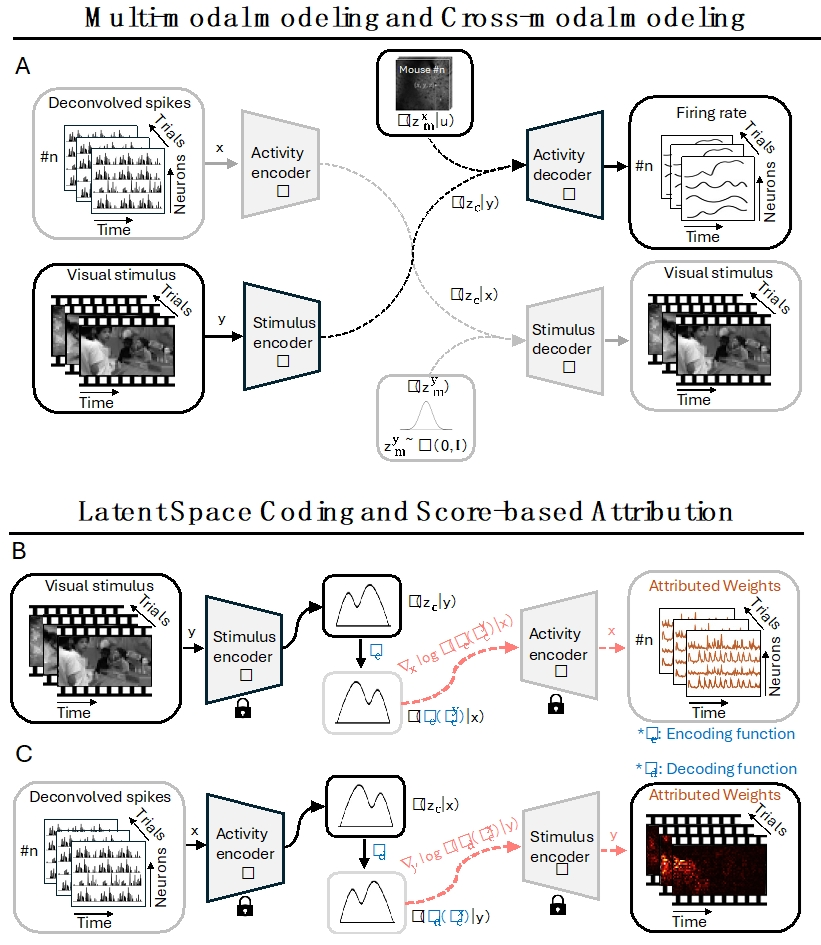
Understanding the functional mechanisms of the primary visual cortex (V1) remains a fundamental challenge in systems neuroscience. Current computational models face two key limitations: the challenge of cross-modal integration between partial neural recordings and complex visual stimuli, and the inherent variability across individuals, including differences in neuron populations and firing patterns. To address these challenges, we propose a multi-modal identifiable variational autoencoder (miVAE) that uses a two-stage disentanglement strategy to map neural activity and visual stimuli into a unified latent space. This framework achieves robust cross-modal correlation identification through fine-grained latent space modeling. We also introduce a novel score-based attribution analysis method to trace latent variables back to their sources in the data space. Evaluation on a large-scale mouse V1 dataset demonstrates our method achieves state-of-the-art performance in cross-individual latent representation and alignment without requiring per-individual fine-tuning, and shows improved performance as data scale increases. Notably, our attribution algorithm successfully identifies distinct neuron subgroups with unique temporal patterns and stimulus discrimination properties, while revealing stimulus regions with specific sensitivity to edge features and luminance changes. This scalable framework offers promising applications for advancing V1 research and broader neuroscience studies.
03. EventZoom: A Progressive Approach to Event-Based Data Augmentation for Enhanced Neuromorphic Vision
Authors: Yiting Dong, Xiang He, Guobin Shen, Dongcheng Zhao, Yang Li, Yi Zeng
Dynamic Vision Sensors (DVS) capture event data with high temporal resolution and low power consumption, providing more efficient solutions than traditional video methods in dynamic and real-time scenarios. Event data augmentation is critical for overcoming the limitations of dataset size and diversity, essential for improving model performance. Comparative experiments show that spatial integrity and temporal continuity are two key factors affecting the effectiveness of event data augmentation, as they preserve the unique sparsity and high dynamic range characteristics of event data. However, existing augmentation methods often overlook these factors. We introduce EventZoom, a novel event data augmentation strategy that employs a temporal progressive approach, embedding transformed samples into original samples through progressive scaling and shifting. The scaling process avoids spatial information loss due to cropping, while the progressive approach prevents disruption or abrupt changes in temporal information. We validated EventZoom across various supervised learning frameworks, with experimental results consistently outperforming existing event data augmentation methods, achieving state-of-the-art performance. We also conducted the first combined semi-supervised and unsupervised learning evaluations to demonstrate the feasibility of event augmentation algorithms, showing EventZoom’s applicability and effectiveness in real-world scenarios with high dynamics and variability.
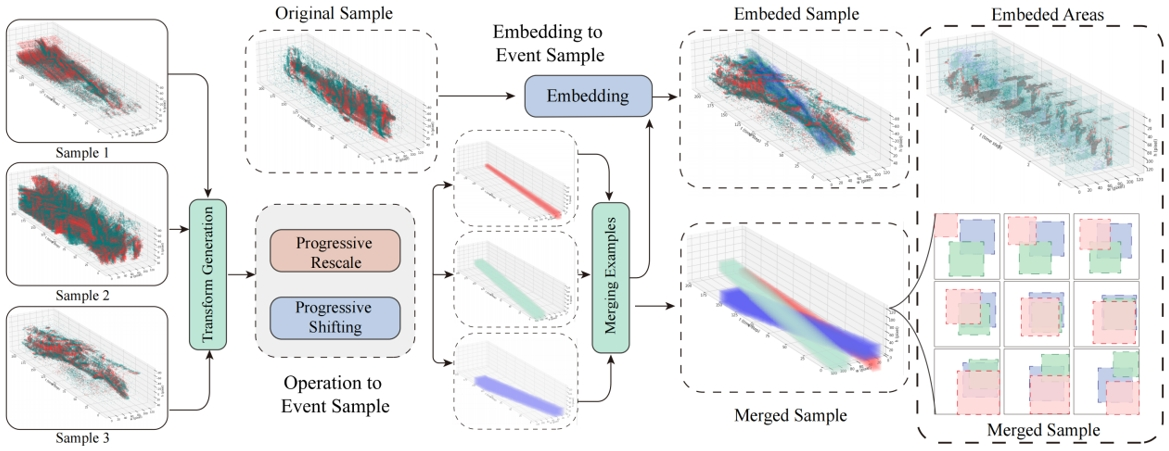
EventZoom data augmentation process. Event samples 1–3 undergo progressive scaling and shifting along the temporal dimension, with the scaled samples embedded into the original samples.
04. StressPrompt: Does Stress Impact Large Language Models and Human Performance Similarly?
Authors: Guobin Shen, Dongcheng Zhao, Aorigele Bao, Xiang He, Yiting Dong, Yi Zeng
Humans frequently experience stress, which significantly impacts their performance. This study explores whether large language models (LLMs) exhibit stress responses similar to humans and how their performance fluctuates under different stress-inducing scenarios. To this end, we designed StressPrompt, a novel prompt set aimed at inducing varying levels of stress. These prompts are carefully crafted based on well-established psychological frameworks and calibrated using human participant ratings. We then applied these prompts to multiple LLMs to evaluate their performance on tasks including instruction following, complex reasoning, and emotional intelligence. Results show that LLMs, like humans, perform best under moderate stress, consistent with the Yerkes–Dodson law. Performance declines under low or high stress conditions. Further analysis indicates that these StressPrompts significantly alter the internal states of LLMs, leading to changes in their neural representations, similar to human responses to stress. This study offers important insights for designing robust and adaptable AI systems in high-stress real-world applications such as customer service, healthcare, and emergency response, and provides a new perspective for broader AI research on how LLMs adapt to different contexts and their parallels with human cognition.
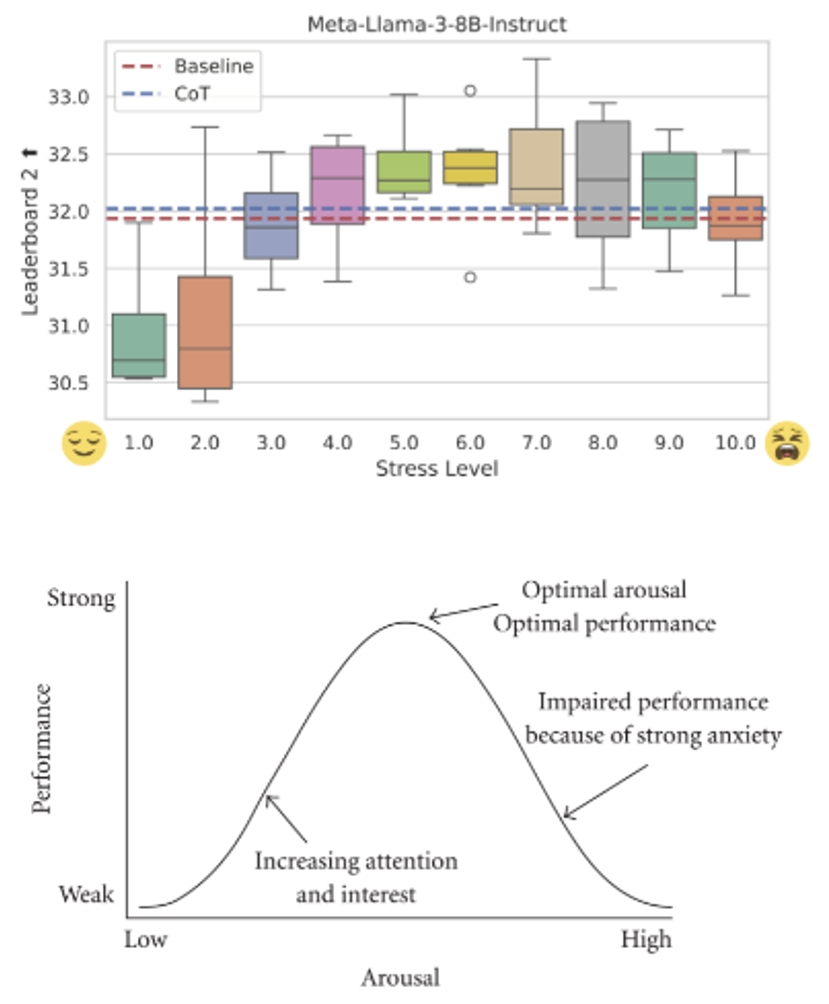
Comparison of LLM and human performance under different stress levels: (a) Leaderboard 2 benchmark performance of Llama-3-8B-Instruct under different stress levels. (b) Illustration of the Yerkes–Dodson law: human performance varies with stress level, peaking at moderate stress and declining at low or high stress. (https://en.wikipedia.org/wiki/Yerkes–Dodson_law)
Copyright Institute of Automation Chinese Academy of Sciences All Rights Reserved
Address: 95 Zhongguancun East Road, 100190, BEIJING, CHINA
Email:brain-ai@ia.ac.cn