2024 NeurIPS Laboratory Selected Works Overview
Font:【B】 【M】 【S】
NeurIPS (Conference on Neural Information Processing Systems) is a top-tier international conference in machine learning and computational neuroscience. NeurIPS 2024 will be held December 9–15 this year in Vancouver, Canada.
1. MetaLA: Unified Optimal Linear Approximation to Softmax Attention MapOral
Authors: Yuhong Chou, Man Yao, Kexin Wang, Yuqi Pan, Ruijie Zhu, Jibin Wu, Yiran Zhong, Yu Qiao, Bo Xu, Guoqi Li
Research Introduction:
The Transformer architecture and self-attention mechanisms have dramatically improved large model performance but introduced quadratic computational complexity with sequence length. Various linear-complexity models, such as Linear Transformer (LinFormer), state-space models (SSM), and linear RNNs (LinRNN), have been proposed as efficient alternatives to self-attention. In this work, we first formally unify existing linear models and summarize their unique characteristics. We then propose three necessary conditions for designing optimal linear attention: dynamic memory capacity, static approximation capability, and minimal parameter approximation. We find that existing linear-complexity models fail to satisfy all three conditions, leading to suboptimal performance. To address this, we propose MetaLA, which satisfies these optimal approximation criteria. Experiments on retrieval, language modeling, image classification, and long-sequence modeling validate MetaLA’s effectiveness.
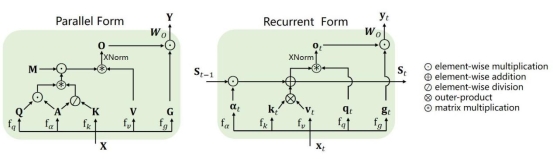
Linear models unified form (parallel and recurrent forms)
2. Learning from Pattern Completion: Self-supervised Controllable Generation
Authors: Zhiqiang Chen, Guofan Fan, Jinying Gao, Lei Ma, Bo Lei, Tiejun Huang, Shan Yu
Research Introduction:
The human brain has strong associative abilities, spontaneously connecting different visual attributes to related scenes, such as linking sketches or doodles with real-world objects. Inspired by neural mechanisms that may support these associative capabilities, particularly cortical modularity and hippocampal pattern completion, we propose a Self-supervised Controllable Generation (SCG) framework. First, we introduce an equivariant constraint to encourage independence across autoencoder modules and correlation within modules, achieving functional specialization. Based on these specialized modules, we then use a self-supervised pattern completion approach for controllable generation training. Experimental results show that the proposed modular autoencoder effectively differentiates functional modules sensitive to color, brightness, and edges, and spontaneously exhibits brain-like properties such as orientation selectivity, color opponency, and center-surround receptive fields. Through self-supervised pattern completion, SCG demonstrates emergent associative generation capabilities, generalizing well to untrained tasks such as paintings, sketches, and ancient murals. Compared to previous representative methods like ControlNet, SCG shows superior robustness in challenging high-noise scenarios and, thanks to its self-supervised approach, offers promising potential for scaling up.
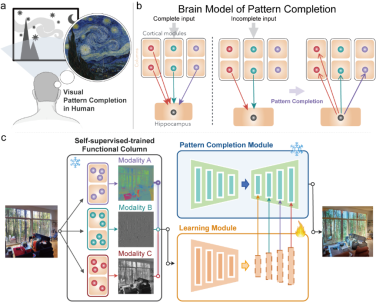
Figure 1. SCG framework. SCG consists of two components: a modular equivariant constraint promoting specialized functional modules, and a pattern completion-based self-supervised controllable generation process.
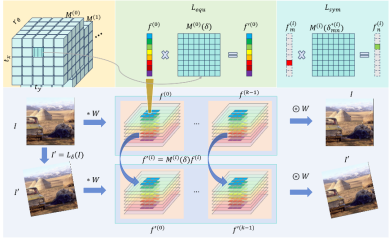
Figure 2. Modular autoencoder architecture with equivariant constraint
3. Neuro-Vision to Language: Enhancing Brain Recording-based Visual Reconstruction and Language Interaction
Authors: Guobin Shen, Dongcheng Zhao, Xiang He, Linghao Feng, Yiting Dong, Jihang Wang, Qian Zhang, Yi Zeng
Research Introduction:
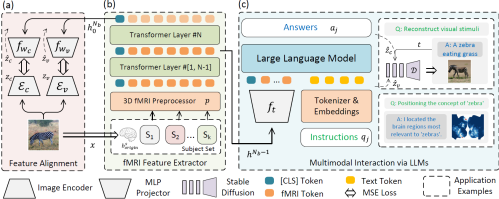
Decoding non-invasive brain signals is critical for advancing our understanding of human cognition but faces challenges due to individual differences and the complexity of neural representations. Traditional approaches often require personalized models and extensive experimentation and typically lack interpretability in visual reconstruction tasks. Our proposed framework leverages Vision Transformer 3D to integrate 3D brain structures with visual semantics, using an efficient unified feature extractor to align fMRI features with multi-level visual embeddings, enabling single-trial data decoding without individual-specific models. This extractor integrates multi-level visual features, simplifying integration with large language models (LLMs). Additionally, we enhanced fMRI datasets with diverse fMRI-image-related text to support the development of multimodal large models. Integration with LLMs improves decoding capabilities, enabling tasks such as brain-signal-based descriptions, complex reasoning, concept localization, and visual reconstruction, precisely identifying language-based concepts from brain signals and enhancing interpretability. This advancement lays a foundation for applying non-invasive brain decoding in neuroscience and human-computer interaction.
Overview of the multimodal integrated framework combining fMRI feature extraction with large language models (LLMs) for interactive communication and reconstruction. The architecture includes: (a) a dual-stream pathway aligning features using VAE and CLIP embeddings; (b) a 3D fMRI preprocessor and feature extractor; (c) multimodal LLMs integrated with fMRI. Extracted features are input to LLMs to handle natural language instructions and generate responses or visual reconstructions.
Copyright Institute of Automation Chinese Academy of Sciences All Rights Reserved
Address: 95 Zhongguancun East Road, 100190, BEIJING, CHINA
Email:brain-ai@ia.ac.cn